Nearly every server application uses some form of caching. Reusing the results of a previous computation can reduce latency and increase throughput, at the cost of some additional memory usage. In this post, we'll see how to create cache efficiently for java programs with the help of examples. In order to understand this concept, you must have an idea about ConcurrentMap, ConcurrentHashMap, Future and FutureTask because these concept are going to helpful while creating Efficient and scaleable cache. This tutorial gives you the basic idea of creating cache

Cache
A cache is a component that transparently stores data so that future requests for that data can be served faster. The data that is stored within a cache might be values that have been computed earlier or duplicates of original values that are stored elsewhere. If requested data is contained in the cache (cache hit), this request can be served by simply reading the cache, which is comparatively faster. Otherwise (cache miss), the data has to be recomputed or fetched from its original storage location, which is comparatively slower. Hence, the greater the number of requests that can be served from the cache, the faster the overall system performance becomes.
Here we would create a Computable wrapper that remembers the results of previous computations and encapsulates the caching process
Basic Approach
The very basic approach we use for caching the result is by using HashMap and Synchronization. In this approach, our basic computation method first checks whether the desired result is already cached and returns the pre-computed values if it is. Otherwise, the result is computed and cached in the HashMap before returning In this example, you'll see the generic approach for creating cache.
This is our computable interface which defines one method compute(), which can be implement by any class whose values we want to cache.

Cache1
 As we know, HashMap is not thread-safe, so to ensure that two threads do not access the HashMap, Cache1 takes the conservative approach of synchronizing the entire compute method. This ensure thread safety but only one thread at a time can execute the compute method at all. If one thread is busy computing a result, others thread calling compute may be locked for a long time. If multiple thread are queued up waiting to compute values not already computed, compute may actually take longer time.
As we know, HashMap is not thread-safe, so to ensure that two threads do not access the HashMap, Cache1 takes the conservative approach of synchronizing the entire compute method. This ensure thread safety but only one thread at a time can execute the compute method at all. If one thread is busy computing a result, others thread calling compute may be locked for a long time. If multiple thread are queued up waiting to compute values not already computed, compute may actually take longer time.
Before moving further, let's see how to use this example in cache1 in our program with the help of a program.
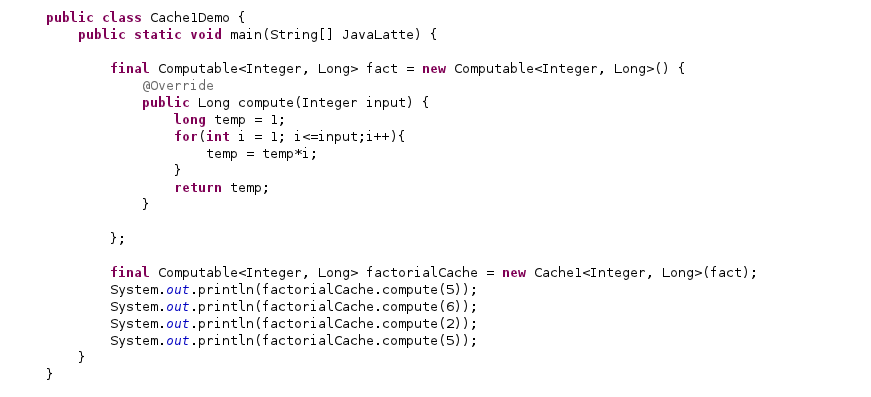 In this example, we have implemented a factorial functionality in order to cache its values. You can see how we have used our interface in generic way.
In this example, we have implemented a factorial functionality in order to cache its values. You can see how we have used our interface in generic way.
First improvement
We can improve on the aweful concurrent behaviour of cache1 by replacing HashMap with ConcurrentHashMap. Since ConcurrentHashMap is thread-safe, there is no need to synchronize when accessing the backing map, thus eliminate the need to of synchronize keyword. So our cache2 certainly has better behaviour than cache1; multiple threads can actually use it concurrently.
Cache2
 But still there is problem with this program, there is chance of vulnerability in which two thread might call the compute method at the same time could end up computing the same value. This is not what we want from our caching - the purpose of a cache is to prevent the same data from being computed multiple times. The problem with cache2 is that if one thread starts an expensive computation, other threads are not aware that computation is in progress and so may start the same computation.
But still there is problem with this program, there is chance of vulnerability in which two thread might call the compute method at the same time could end up computing the same value. This is not what we want from our caching - the purpose of a cache is to prevent the same data from being computed multiple times. The problem with cache2 is that if one thread starts an expensive computation, other threads are not aware that computation is in progress and so may start the same computation.
Figure shows that Thread X is currently computing f(5) in the mean time other thread Y might need to compute f(5) and it sees that f(5) is not in cache and it think let's calculate f(5).

Second improvement
As you have seen in the previous image that Thread X is currently computing f(5), so that if another thread arrives looking for f(5), it knows that most efficient way to find it is to head over Thread X house, hang out there until X is finished and then ask "Hey dude, what did you get for f(5)?"
Now, here come FutureTask into picture. FutureTask is a cancellable asynchronous computation. FutureTask represents a computational process that may or may not already have completed. FutureTask.get methods returns the result of the computation immediately if it is available; otherwise it blocks until the result has been computed and then returns it.
Now, for instead of storing the cache value we use Future<R> in ConcurrentHashMap. In this program, we first checks to see if the requested calculation has been started. If not, we create a FutureTask, register with the map and starts the computation; otherwise waits for the result of the existing calculation. The result might be available immediately or in the process of being computed.
Cache3

 The cache3 is almost perfect; it exhibits very good concurreny, the result is returned efficiently if is known and if the computation is in process by another thread, the newly thread wait patiently for the result. It has only one defect there is still a chance of vulnerability in which two threads might compute the same value. The if block in compute is still not-atmoic like first check and then act type of sequence, it is possible for two threads to call compute with same value, both see that the cache does not contain the desired result and both start computation.
The cache3 is almost perfect; it exhibits very good concurreny, the result is returned efficiently if is known and if the computation is in process by another thread, the newly thread wait patiently for the result. It has only one defect there is still a chance of vulnerability in which two threads might compute the same value. The if block in compute is still not-atmoic like first check and then act type of sequence, it is possible for two threads to call compute with same value, both see that the cache does not contain the desired result and both start computation.

Third improvement
Cache3 is vulnerable because a compound action is performed on the backing map that cannot be made atomic using locking. Two Thread thread might see result == null at the same time and starting calculating the same value.
In order to avoid this we take advantage of atomic putIfAbsent method of concurrentMap.
V putIfAbsent(K key,V value)

Cache4


Final Improvement
Caching a Future instead of a value creates the possibility of cache pollution; if a computation is cancelled or fails, future attempts to compute the result will also indicate cancellation or failure. To avoid this, we remove Future from cache if computation cancelled or upon RuntimeException if the computation might succeed on a future attempt

 This is our final cache program. I hope you understood the basic concept of writing cache program in Java. Even you can further improve this program by adding cache expiration time with each result by using a subclass of FutureTask and periodically scanning the cache for expired entries.
This is our final cache program. I hope you understood the basic concept of writing cache program in Java. Even you can further improve this program by adding cache expiration time with each result by using a subclass of FutureTask and periodically scanning the cache for expired entries.
If you know anyone who has started learning Java, why not help them out! Just share this post with them.Thanks for studying today!...
Cache
A cache is a component that transparently stores data so that future requests for that data can be served faster. The data that is stored within a cache might be values that have been computed earlier or duplicates of original values that are stored elsewhere. If requested data is contained in the cache (cache hit), this request can be served by simply reading the cache, which is comparatively faster. Otherwise (cache miss), the data has to be recomputed or fetched from its original storage location, which is comparatively slower. Hence, the greater the number of requests that can be served from the cache, the faster the overall system performance becomes.
Here we would create a Computable wrapper that remembers the results of previous computations and encapsulates the caching process
Basic Approach
The very basic approach we use for caching the result is by using HashMap and Synchronization. In this approach, our basic computation method first checks whether the desired result is already cached and returns the pre-computed values if it is. Otherwise, the result is computed and cached in the HashMap before returning In this example, you'll see the generic approach for creating cache.
This is our computable interface which defines one method compute(), which can be implement by any class whose values we want to cache.
Cache1
Before moving further, let's see how to use this example in cache1 in our program with the help of a program.
First improvement
We can improve on the aweful concurrent behaviour of cache1 by replacing HashMap with ConcurrentHashMap. Since ConcurrentHashMap is thread-safe, there is no need to synchronize when accessing the backing map, thus eliminate the need to of synchronize keyword. So our cache2 certainly has better behaviour than cache1; multiple threads can actually use it concurrently.
Cache2
Figure shows that Thread X is currently computing f(5) in the mean time other thread Y might need to compute f(5) and it sees that f(5) is not in cache and it think let's calculate f(5).
Second improvement
As you have seen in the previous image that Thread X is currently computing f(5), so that if another thread arrives looking for f(5), it knows that most efficient way to find it is to head over Thread X house, hang out there until X is finished and then ask "Hey dude, what did you get for f(5)?"
Now, here come FutureTask into picture. FutureTask is a cancellable asynchronous computation. FutureTask represents a computational process that may or may not already have completed. FutureTask.get methods returns the result of the computation immediately if it is available; otherwise it blocks until the result has been computed and then returns it.
Now, for instead of storing the cache value we use Future<R> in ConcurrentHashMap. In this program, we first checks to see if the requested calculation has been started. If not, we create a FutureTask, register with the map and starts the computation; otherwise waits for the result of the existing calculation. The result might be available immediately or in the process of being computed.
Cache3
Third improvement
Cache3 is vulnerable because a compound action is performed on the backing map that cannot be made atomic using locking. Two Thread thread might see result == null at the same time and starting calculating the same value.
In order to avoid this we take advantage of atomic putIfAbsent method of concurrentMap.
V putIfAbsent(K key,V value)
Cache4
Final Improvement
Caching a Future instead of a value creates the possibility of cache pollution; if a computation is cancelled or fails, future attempts to compute the result will also indicate cancellation or failure. To avoid this, we remove Future from cache if computation cancelled or upon RuntimeException if the computation might succeed on a future attempt
If you know anyone who has started learning Java, why not help them out! Just share this post with them.Thanks for studying today!...
No comments:
Post a Comment